近期,OpenI啟智社區召集了技術委員會成員針對社區重點項目進入孵化培育管道的評審決策會議,最終共計通過2個重點開源項目的貢獻申請,分別是來自鵬城實驗室開源所貢獻的鵬程·盤古α項目與來自智源語言大模型加速技術創新中心貢獻的OpenBMB項目。
恭喜這2個項目正式進入啟智社區開源項目孵化管道,它們豐富了OpenI啟智社區在模型儲備方面的內容,進一步完善社區總體技術架構。
PanGu-α
2000億參數中文自回歸大模型
貢獻者:鵬城實驗室
許可證:Apache License 2.0
項目地址:https://git.www.cfcf666.com/PCL-Platform.Intelligence
鵬程·盤古α是業界首個2000億參數以中文為核心的預訓練生成語言模型,目前開源了兩個版本:鵬程·盤古α和鵬程·盤古α增強版,并支持NPU和GPU兩個版本,支持豐富的場景應用,在知識問答、知識檢索、知識推理、閱讀理解等文本生成領域表現突出,具備較強的少樣本學習的能力。例如:
Input: 中國和美國和日本和法國和加拿大和澳大利亞的首都分別是哪里? Generate: 中國的首都是北京,美國的首都是華盛頓,日本的首都是東京,法國的首都是巴黎,澳大利亞的首都是堪培
基于盤古系列大模型提供大模型應用落地技術幫助用戶高效的落地超大預訓練模型到實際場景。
整個框架特點如下:
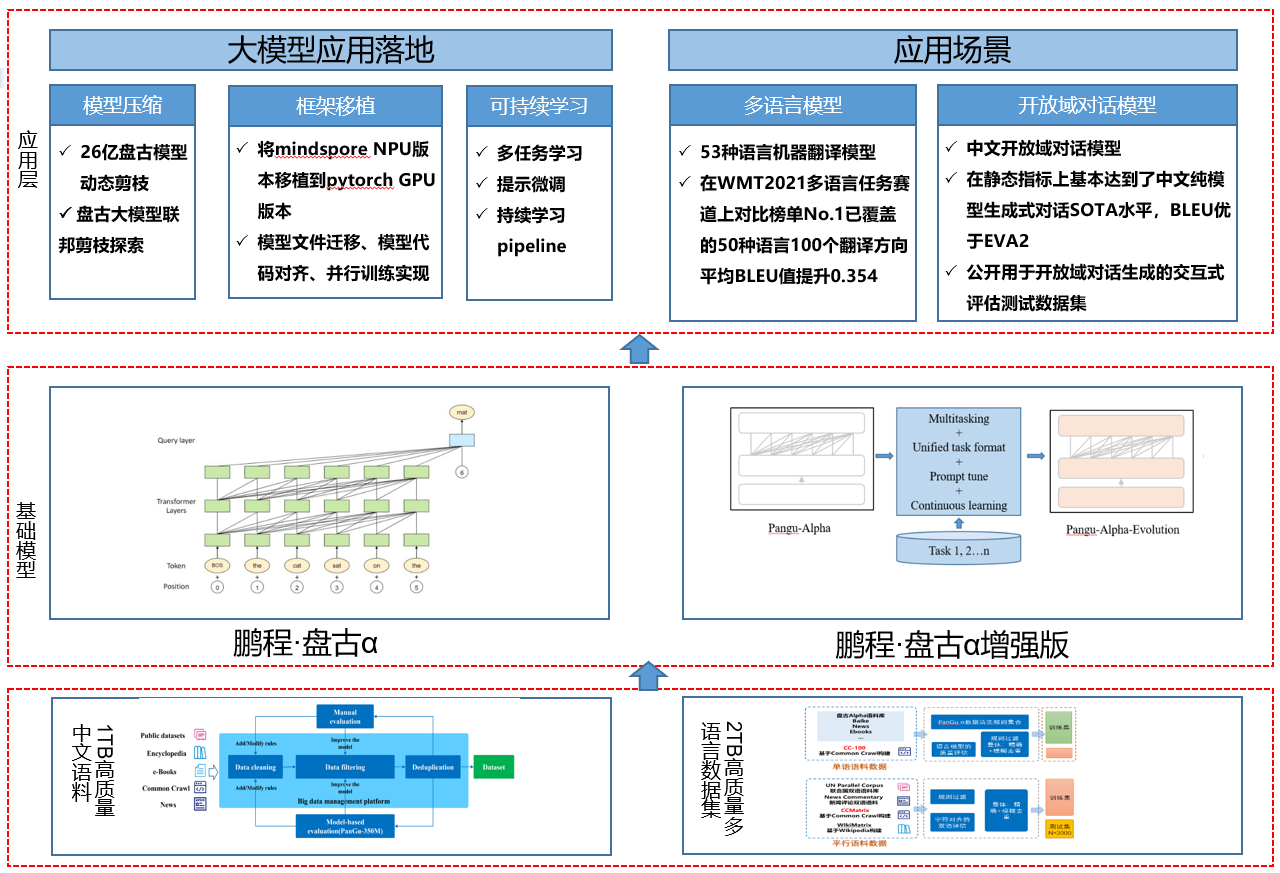
主要有如下幾個核心模塊:
數據集:從開源開放數據集、common crawl數據集、電子書等收集近80TB原始語料,構建了約1.1TB的高質量中文語料數據集、53種語種高質量單、雙語數據集2TB。
基礎模塊:提供預訓練模型庫,支持常用的中文預訓練模型,包括鵬程·盤古α、鵬程·盤古α增強版等。
應用層:支持常見的NLP應用比如多語言翻譯、開放域對話等,支持預訓練模型落地工具,包括模型壓縮、框架移植、可持續學習,助力大模型快速落地。
正在進行的開源工作有:
應用組件:為快速適配用戶的應用場景,將推出基于盤古大模型的一系列組件,如微調、壓縮、框架遷移等,實現一鍵式微調和模型遷移功能。
云服務提供:結合智算網絡提供模型訓練、微調、壓縮等開源應用創新的算力支持,優化基礎大模型的云服務能力,支持本地調用的同時,也可以在云上實現調用,給用戶帶來高效的從訓練到落地的完整體驗。
盤古α項目已在OpenI啟智社區實現了數據、算法、模型和服務的逐步全面開源開放,希望以OpenI啟智開源社區為載體,集眾智、聚眾力,吸引開發者共同參與到模型的壓縮輕量化和應用創新工作中,不斷探索“盤古α”模型的強大潛力。

Open Lab for Big Model Base
大規模預訓練語言模型庫與相關工具
貢獻者:清華大學、北京智源人工智能研究院語言大模型加速技術創新中心、ModelBest
許可證:Apache License 2.0
項目地址:https://git.www.cfcf666.com/OpenBMB
OpenBMB全稱為Open Lab for Big Model Base,旨在打造大規模預訓練語言模型庫與相關工具,加速百億級以上大模型的訓練、微調與推理,降低大模型使用門檻,與國內外開發者共同努力形成大模型開源社區,推動大模型生態發展,實現大模型的標準化、普及化和實用化,讓大模型飛入千家萬戶。
OpenBMB將努力建設大模型開源社區,團結廣大開發者不斷完善大模型從訓練、微調、推理到應用的全流程配套工具。
基于貢獻者團隊前期工作,OpenBMB設計了大模型全流程研發框架,并初步開發了相關工具,這些工具各司其職、相互協作,共同實現大模型從訓練、微調到推理的全流程高效計算。

OpenBMB開源社區推崇簡潔,追求極致,相信數據與模型的力量。歡迎志同道合的開發者們加入,共同為大模型應用落地添磚加瓦,早日讓大模型飛入千家萬戶。
OpenI啟智社區從服務新一代人工智能重大科技項目出發,為我國的新一代人工智能發現項目、培育項目、檢驗項目和推廣項目。目前,社區已孵化33個重點開源項目,形成包含基礎設施、軟件環境、算法框架、模型儲備、應用開發部署的多維度、全流程的社區開源技術體系。
社區堅持以開放的心態與國內外的社區、項目合作,也在“尊重創新”的原則下, 歡迎有志于AI開源事業的開發者加入社區,共同促進AI開源開放生態體系建設。如有意貢獻項目和參與社區孵化培育的個人或組織,請參考《啟智社區項目開源指南》提供項目相關材料。