當(dāng)前位置:首頁 > 資訊 > 社區(qū)動(dòng)態(tài) >
數(shù)據(jù)作為數(shù)字經(jīng)濟(jì)的核心生產(chǎn)要素,只有將各地區(qū)各個(gè)領(lǐng)域間數(shù)據(jù)要素流通交易起來,才能夠充分釋放數(shù)據(jù)要素價(jià)值。
鵬城實(shí)驗(yàn)室率先開放大規(guī)模高質(zhì)量中文語料數(shù)據(jù)集(鵬程·盤古語料數(shù)據(jù)集-1.1TB高質(zhì)量中文語料數(shù)據(jù)、一帶一路多語言語料數(shù)據(jù)集-1TB高質(zhì)量多語言語料數(shù)據(jù)),研究人員可在鵬城AI靶場(chǎng)上安全使用數(shù)據(jù),但無法帶走數(shù)據(jù)。若用戶不愿上傳自身數(shù)據(jù)到鵬城AI靶場(chǎng),可通過鵬城眾智協(xié)同計(jì)算平臺(tái)AISynergy使用本地語料數(shù)據(jù)與鵬城AI靶場(chǎng)數(shù)據(jù)進(jìn)行聯(lián)合訓(xùn)練或微調(diào)。

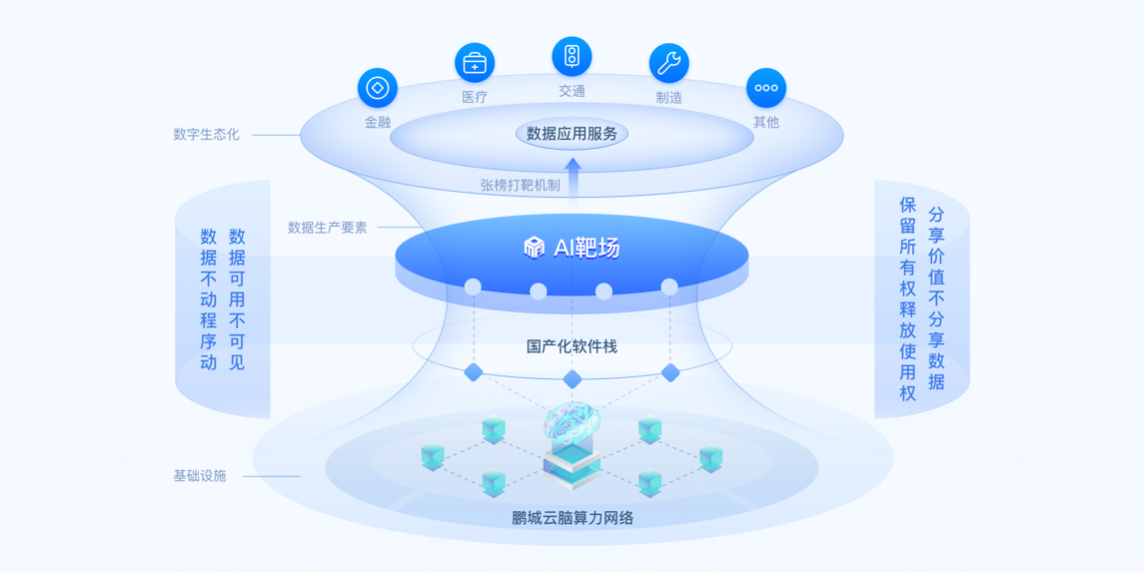
鵬城AI靶場(chǎng)是基于方濱興院士提出的“數(shù)據(jù)不動(dòng)程序動(dòng)、數(shù)據(jù)可用不可見、分享價(jià)值不分享數(shù)據(jù)、保留所有權(quán)釋放使用權(quán)”隱私保護(hù)新理念,由鵬城實(shí)驗(yàn)室新型網(wǎng)絡(luò)部平臺(tái)所研發(fā)的數(shù)據(jù)要素流通交易新型基礎(chǔ)設(shè)施平臺(tái)。
鵬城AI靶場(chǎng)提出了一個(gè)模型加工場(chǎng)的方法,其基本思想是要構(gòu)造一個(gè)可信的執(zhí)行環(huán)境,這個(gè)可信的執(zhí)行環(huán)境不完全等同于傳統(tǒng)的可信執(zhí)行環(huán)境TEE。傳統(tǒng)的可信執(zhí)行環(huán)境是強(qiáng)調(diào)計(jì)算環(huán)境可信,不會(huì)被攻擊。鵬城AI靶場(chǎng)把一些人為的因素放在里面,把社會(huì)工程因素放在里面,以構(gòu)建一個(gè)安全可控的區(qū)域。這個(gè)安全可控包括人員可控,能落實(shí)責(zé)任制。如在政府部門或者國企里構(gòu)造一個(gè)安全可控區(qū)域,再通過“數(shù)據(jù)不動(dòng)程序動(dòng)”“數(shù)據(jù)可用不可見”的方法來保證隱私。
在鵬城AI靶場(chǎng)架構(gòu)中,數(shù)據(jù)擁有方需要把數(shù)據(jù)放到模型加工場(chǎng)里,數(shù)據(jù)所有者可以決定數(shù)據(jù)是否能夠被平臺(tái)所使用。
鵬城實(shí)驗(yàn)室網(wǎng)絡(luò)智能部高效能云計(jì)算所團(tuán)隊(duì)與鵬城AI靶場(chǎng)團(tuán)隊(duì)聯(lián)合研制了具有大規(guī)模語料數(shù)據(jù)安全保護(hù)功能的鵬城眾智AI協(xié)同計(jì)算平臺(tái)AISynergy 2.0版,可完成跨多個(gè)計(jì)算集群的協(xié)同計(jì)算作業(yè),實(shí)現(xiàn)基于中國算力網(wǎng)(C2NET)的全新計(jì)算范式和數(shù)據(jù)隱私安全分布式業(yè)務(wù)場(chǎng)景,如跨域大模型協(xié)同訓(xùn)練與微調(diào)、多中心模型聚合、多中心聯(lián)邦學(xué)習(xí)等。以下是典型應(yīng)用場(chǎng)景介紹:
典型場(chǎng)景1:AI靶場(chǎng)上開放語料數(shù)據(jù),用戶可直接使用或上傳數(shù)據(jù)到AI靶場(chǎng)完成聯(lián)合訓(xùn)練場(chǎng)景
研究團(tuán)隊(duì)從Common Crawl、電子書、百科全書、新聞等廣泛的資源中收集了大量的原始數(shù)據(jù)。
在此基礎(chǔ)上,對(duì)數(shù)據(jù)進(jìn)行多重過濾和清洗,確保處理后的數(shù)據(jù)具有高質(zhì)量和多樣性。經(jīng)過復(fù)雜的預(yù)處理,得到大規(guī)模高質(zhì)量中文語料數(shù)據(jù)集,這些語料數(shù)據(jù)集經(jīng)過預(yù)處理后具有重要數(shù)據(jù)價(jià)值,但由于很難保證其中沒有涉及敏感或安全隱私的數(shù)據(jù)內(nèi)容,直接開放具有較大風(fēng)險(xiǎn)。
通過AI靶場(chǎng),研究人員可安全使用這些語料數(shù)據(jù),但無法帶走數(shù)據(jù),實(shí)現(xiàn)數(shù)據(jù)不流出,充分發(fā)揮語料數(shù)據(jù)價(jià)值,助推自然語言處理等基礎(chǔ)研究的協(xié)作快速發(fā)展。
請(qǐng)參考示例:
【如何上傳您自己的語料到靶場(chǎng),與盤古部分語料進(jìn)行聯(lián)合訓(xùn)練?】
【多語言mPanGu,單機(jī)、多卡+單方、多方數(shù)據(jù)協(xié)同訓(xùn)練場(chǎng)景】
典型場(chǎng)景2:AI靶場(chǎng)上語料數(shù)據(jù)與第三方本地自有數(shù)據(jù)開展協(xié)同計(jì)算場(chǎng)景
若研究人員有自有語料數(shù)據(jù),但不愿將自有數(shù)據(jù)上傳至AI靶場(chǎng),可以通過協(xié)同計(jì)算的方式進(jìn)行訓(xùn)練。研究人員在AI靶場(chǎng)和本地分別進(jìn)行模型訓(xùn)練,通過協(xié)同計(jì)算平臺(tái)AISynergy,可完成跨多個(gè)智算中心的協(xié)同計(jì)算作業(yè),實(shí)現(xiàn)多中心數(shù)據(jù)價(jià)值利用最大化及協(xié)同計(jì)算應(yīng)用賦能新范式。
請(qǐng)參考示例:
AI靶場(chǎng)通過調(diào)試環(huán)境與運(yùn)行環(huán)境分離體系架構(gòu)以及仿真數(shù)據(jù)生成、隱私保護(hù)前提下的調(diào)試等創(chuàng)新技術(shù),確保數(shù)據(jù)所有權(quán)和使用權(quán)分離,可以讓更多的數(shù)據(jù)提供方敢于將其數(shù)據(jù)安全托管,讓更多的數(shù)據(jù)使用方能夠充分挖掘真實(shí)場(chǎng)景真實(shí)數(shù)據(jù)。
目前AI靶場(chǎng)依托以鵬城云腦為樞紐節(jié)點(diǎn)的中國算力網(wǎng)提供的強(qiáng)大算力資源,通過構(gòu)建可信數(shù)據(jù)空間,以張榜打靶方式將數(shù)據(jù)安全開放,進(jìn)而篩選具有核心競(jìng)爭(zhēng)力的AI團(tuán)隊(duì), 實(shí)現(xiàn)數(shù)據(jù)應(yīng)用集智創(chuàng)新。
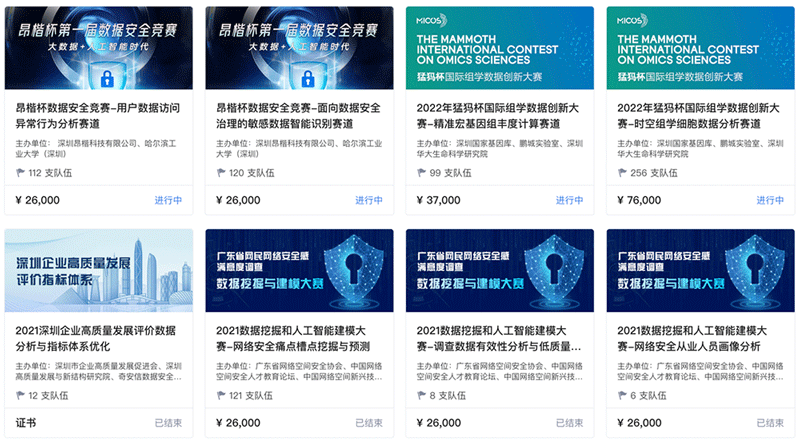
AI靶場(chǎng)目前已有力支撐了“2022年猛犸杯國際組學(xué)數(shù)據(jù)創(chuàng)新大賽”“昂楷杯第一屆數(shù)據(jù)安全競(jìng)賽”“廣東省網(wǎng)絡(luò)安全協(xié)會(huì)數(shù)據(jù)挖掘大賽”、“深圳企業(yè)高質(zhì)量發(fā)展評(píng)價(jià)指標(biāo)體系”、 “騰景AI經(jīng)濟(jì)預(yù)測(cè)”等多個(gè)重要領(lǐng)域的數(shù)據(jù)安全開放。
大規(guī)模高質(zhì)量中文語料數(shù)據(jù)集安全開放開源社區(qū)